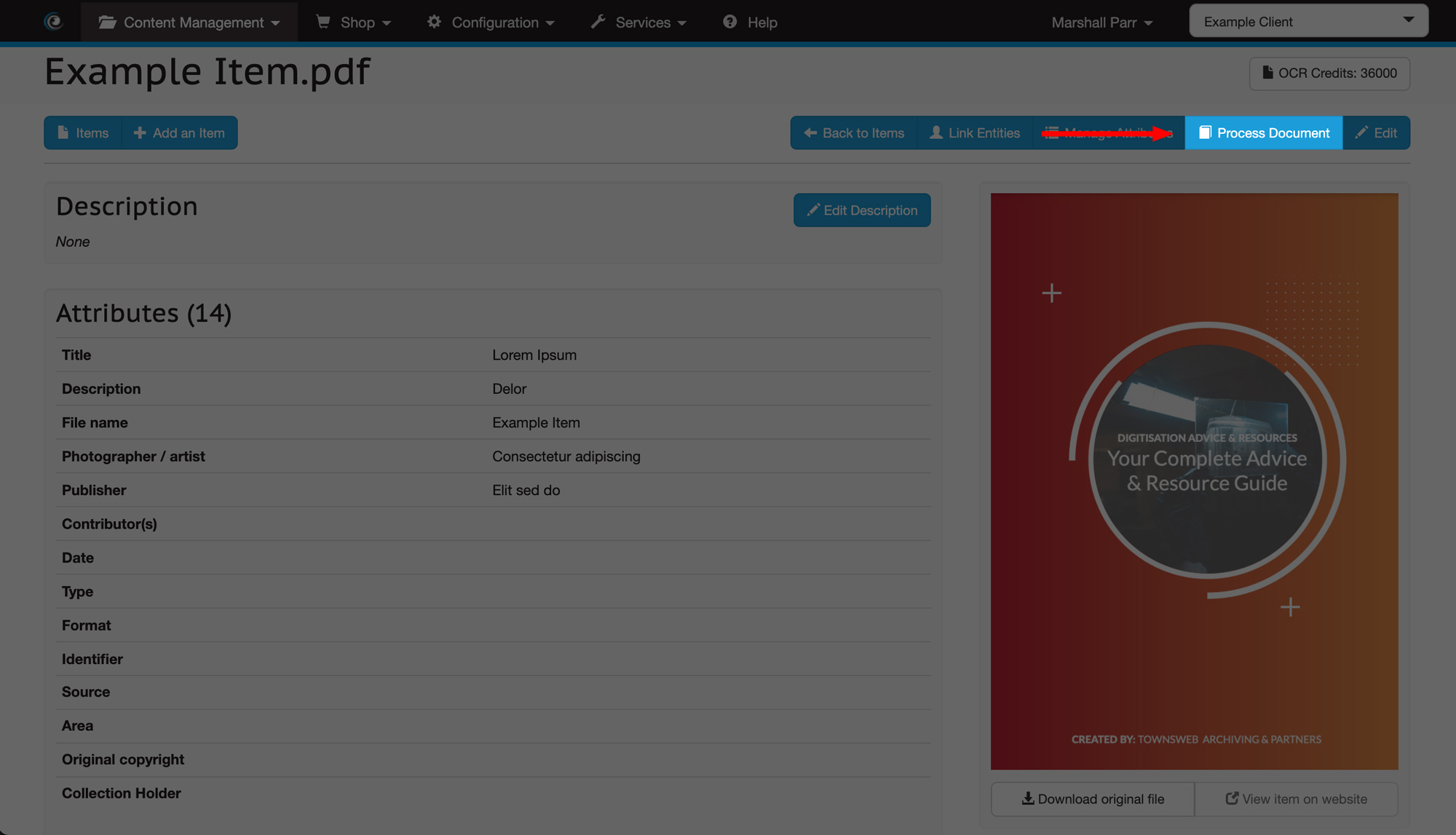
We have just released a new feature specifically for use with your PDF documents. This feature enables you to extract the text from PDFs as an alternative to using your OCR credits.
You now have two options:
Option 1 - OCR (Optical Character Recognition) technology visually detects the text within the document. This is most suited to text stored as an image within a document and uses your OCR credits.
Option 2 - Text Extraction takes text directly from the original document contents, in a similar way to highlighting and copying text. This option is free of charge.
Important notes on text extraction:
- Currently only PDF documents support text extraction.
- Document settings have changed to hide the original document by default rather than delete it when converted to a PastView collection.
- Already imported documents will not be able to use the Text Extract feature unless the original document has been kept in the system.
- It is possible to 're-process' documents that have already been imported to change settings.